一如往常使用公司學習日,這次輪到Mesh Shader了
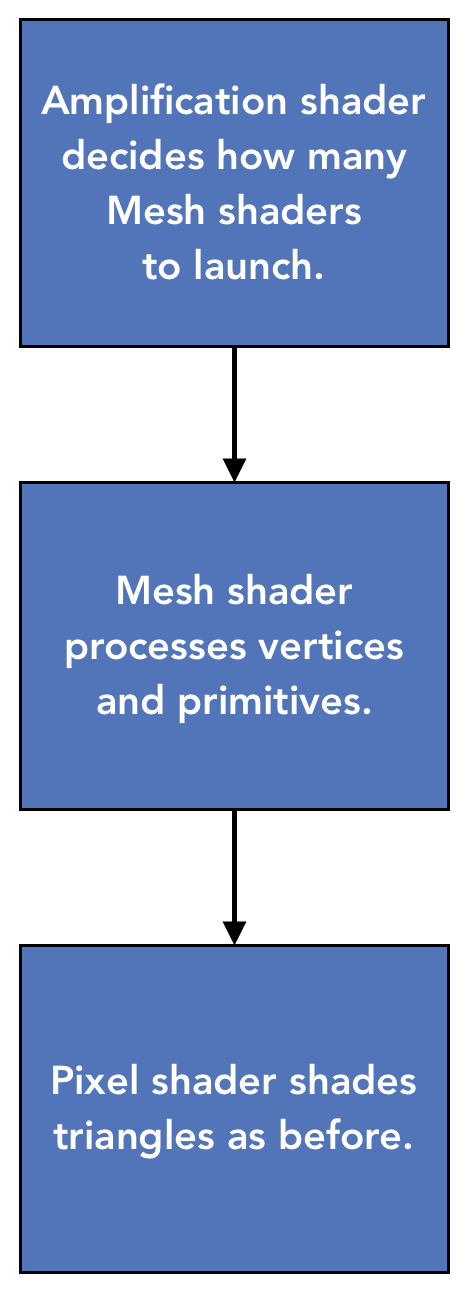
Mesh Shader基本上讓彩現流程簡化為:
省去了Input Assembly, Vertex Shader, Geometry/Tessellation Shader等等階段
(或者應該說,Mesh Shader處理IA/VS的部分,而GS/TS則要使用Amplification Shader)
以類似於Compute Shader的方式來處理網格,對於GPU來說可能可以改善執行緒效率
而後續的光柵化/Pixel Shader部分不變,簡單想成從vertex-to-pixel變成mesh-to-pixel即可
然後從下Draw call變成下Dispatch call,這也表示用async compute來處理網格是有可能的
(但免不了架構大改)
硬限制為GPU必須至少支援Shader Model 6.5以上,同時也要支援Mesh shader tier 1
參考資料
CPU端實作
PSO的初始化如下:
與一般PSO初始化無異,只是結構換成MS專用的
呼叫Shader的方式如下:
直接把網格資料綁到Shader即可 (包含頂點、submesh資訊、index等等)
完全不用再呼叫IASetVertexBuffers之類的指令
CPU端的實作挺單純的
GPU端實作
天底下沒有免費的午餐,既然CPU端節省了很多寫法,那自然就是轉嫁到GPU端了
來看一下範例的Mesh shader:
看似只有短短幾行,但不了解其性質的話也無法運用自如
完整檔案連結
先從寫死的數字說起
- 與Compute shader一樣,需要指定numthreads()屬性,上限為x*y*z = 128,寫死128,1,1是基於這個原因,上限比起compute shader小得多。
- 輸出的vertices以及indices上限為256,所以說正常情況,把一個模型的網格切成好幾份來處理是必須的了。這邊微軟範例分別寫死126跟 在中國不存在的數字 。
SetMeshOutputCounts()則是MS的內建函式之一,告訴GPU我們要輸出的數量
- 每個MS一定要呼叫一次,如果有用if else造成不同的執行路徑,那每一條路徑都要呼叫
- 必定只能在輸出之前呼叫,以上圖為例,如果把SetMeshOutputCounts放在最後一行,那Validation Layer就會出來哭
SV_GroupID跟SV_GroupThreadID與一般的CS毫無差別
- 這個範例在CPU端下的指令是DispatchMesh(2263,1,1),整個模型分成2263個子集合來處理,所以gid的範圍是[0, 2262],而gtid自然是[0, 127]了
- 所以以這範例而言,這個模型有2263個Thread group在處理,而128個Threads負責不同位置的網格
其他部分就是自製化的部分了,微軟這邊在Meshlet這個自製結構存放了頂點數量+位移、三角形數量+位移等等,並且做後續的處理。
在GetVertexAttributes()裡可以看到vertex to pixel基本上是一樣的運算,只不過這次要自己indexing正確的頂點資訊,彈性相當高。
範例還順便秀了一波把indices從一個32-bit數字展開為三個10-bit的操作,這意味著網格壓縮/解壓縮更好處理了,過往開發者就是非得讓輸入為16-bit/32-bit index不可(於CPU端解壓),現在可以壓得更低且即時在GPU展開了。
D3D12MeshletRender範例的結果:
關於Mesh Culling
另一個範例D3D12MeshletCull展示了在GPU上做culling的方式
同時用上了Amplification shader跟Mesh shader
IsVisible裡面是一般的frustum culling,這裡根據visible的結果再呼叫一次DispatchMesh()。
而CPU端的呼叫現在是為了Amplification shader。
完全把culling移到GPU上不是問題,但會變好還是變壞還是要看設計。
另外這裡總算是看到了Wave operation的有效應用範例,傳統作法是利用InterlockedAdd之類的指令來計算那個visibleCount,但就是需要去做group的共享記憶體存取跟同步,有了wave操作更加靈活高效。
關於Mesh Instancing
當然是沒有DispatchMeshInstanced()這種東西,一樣要自己輸入資料並在MS實作。
帶入Instance的資料方式不外乎就是再餵一個structuredbuffer,設計上真的很自由
動態LOD的應用也有範例就不贅述
============================================================
又學了一招啊~越來越多工作能夠完全放在GPU了
未來的大作,GPU使用率衝滿但是CPU悠哉的情況會越來越多吧xd
不過這東西要完全普及,引擎架構勢必要有變動,要完全普及大概還要幾年吧