來源
直接跳過上部份大量關於至少n2p甚至A16才可能會涉及到背面電源網路。
跳到現代架構比較注重的SRAM部份。
摘自其中一段:
single-fin since Intel 22nm, the 1st finFET process. Backside power offers little benefit as bit cell routing is already optimized.
自從intel 22nm這個第一個finfet製程以來,由於位元線已經改進,所以背面電源幾乎沒有改善。
Transistor length and width reduction is the strongest lever for SRAM bit cell scaling. Compared to a single-fin device, a GAA transistor is slightly smaller since the transistor channel length and spacing between transistors can be reduced. This means the bit cells will see a one-time scaling benefit in the change from finFET to GAA, but likely not much in follow-on nodes.
電晶體的長度與寬度減少是SRAM單元縮放的最有效手段,與單鰭相比GAA電晶體更小,因為電晶體通道長度與電晶體的間距可以減少。這意味著位元單元將從finfet到GAA的轉換中獲得一次縮放改善,但在後續節點可能不會有優勢。
Contacts, connecting transistors in the bit cell to power and signal, also restrict cell scaling. They must be large enough to form a low-resistance connection and maintain a minimum separation to avoid shorting between adjacent contacts. These are scaling slowly as well with advances in material engineering.
位元單元中的電晶體連接到電源與訊號的接點限制了單元縮放。所以它們必須足夠大,以形成足夠低的電阻連接並保持最小化間距,以避免相鄰觸點短路。隨著材料工程的進步,這些規模也在逐漸變大。
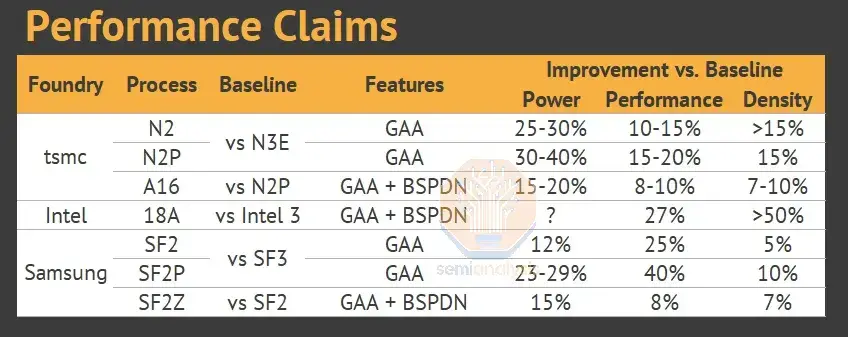
SRAM periphery, like other logic, still benefits from modern DTCO (design technology co-optimization) and other scaling techniques. When TSMC claims as 22% SRAM density improvement from N3E to N2, it comes mostly from periphery scaling. Unfortunately, in key applications such as working memory and L2 or L3 caches, periphery is only a small percentage of the total SRAM area and thus the benefits will not be as strong here. Overall performance improvements, if they meet claims, will come primarily from logic cells, not SRAM.
SRAM外圍電路與其它邏輯一樣,仍能受到DTCO(設計技術協同改進)和其他縮放技術。台積電聲稱SRAM密度從n3e到n2提高了22%,但這主要來自於外圍擴展。不幸的是,在工作記憶體與L2或L3快取等關鍵應用中,外圍電路僅佔SRAM總面積的一小部份,因此優勢可能不會如此明顯。整體性能改進(如果符合要求)將主要來自邏輯單元而非SRAM。
_________
finfet到GAA會獲得一次改進,而GAA到CFET也能再獲得一次改進。
除了IO還在16nm,因為analog有著複雜的規則所以更受很多物理限制,例如需要思考訊號和雜訊比,複雜的雜訊例如熱雜訊、電壓雜訊、電流雜訊、半導體本身缺陷一大堆,這些公式計算後難以微縮,也難以降低功耗,因為訊號的能量不太可能弱於雜訊,否則將難以區分。
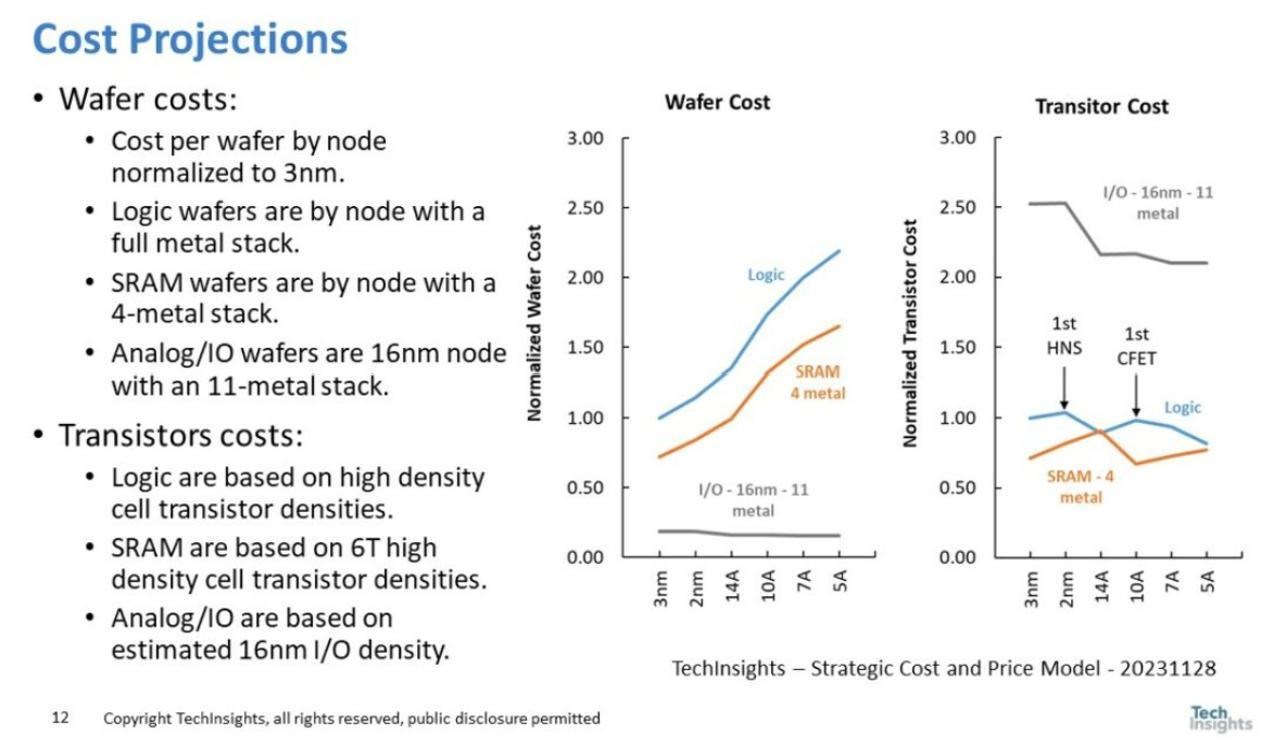
不過即使如此,整體單位面積仍然還是持續大幅上漲,而且進步幅度也不是很大,可以根據成本和單位面積來估算密度提升...
盡管按上述所說SRAM能在finfet轉變到GAA時獲得一次SRAM縮放,但仍然在SRAM方面成本上漲,而僅只有到CFET(比利時技術中心路線圖約估2030-2032才能上線?)才能看到一次SRAM成本再次下迭,估計是密度可以接近翻倍?
不過看情況A16/A14可能會是一個在邏輯方面成本較低的製程,而轉變到CFET會上漲一次,盡管後續A7甚至A5仍能繼續降低,只是估計都十年後了很難講。
整體來說摩爾定律若以每兩年翻倍的定義來說早就死了,或單位電晶體成本仍有機會緩慢下降,然而很有限,雖然單位電晶體性能也在上漲來抵銷漲價的幅度。
而若要考慮到背面供電和更複雜的銅互連問題,隨著RC和RLC影響增大,金屬層性能在每1mm帶來的delay將會增長至1500ps乃至更高的幅度吧,已經到了需要非常重視的地步了。
為了讓整個晶片的性能更好看且能效有效的提升,SRAM的佔比將會到達一個極其恐怖的地步,畢竟需要紀錄狀態都需要用到SRAM,而幾乎整個微架構無論暫存器、快取等和管線化無一不例外,都是需要SRAM。
SRAM受到的動態、靜態雜訊限制更多,電荷內容翻轉的問題將更嚴重更複雜,而邏輯很難輔助SRAM多少,因為實現過於複雜的計算於內進行改善將引入更多邏輯的延遲,這可能帶來頻率下降,或在管線化的情況下增長延遲而維持吞吐,利用率整體更差。
而隨著DRAM的進步幅度小,也同樣碰上需要大量使用EUV才能繼續微縮至10nm乃至以下,雖然製程定義上與邏輯製程完全不同就是了,但成本也將大幅上升。
而這些種種問題又繼續加劇了片上的快取需要持續增加而且增加幅度越大,還需要有更大的外圍來提供足夠大的頻寬,複雜化的設計...
而末級快取(LLC)或低等級快取如GPU方面牽涉到Crossbar互連,而CPU方面也有Ring和Mesh互連拓樸等問題,對設計的要求更難。
也不知道未來是否有更好的演算法、計算方式和更好的工作流程,或是有更好的權衡分析取捨來改善這些問題,否則未來將受制獲取資料的能力,當資料越大就越難處理。