任何一個資訊產生的過程都可以視為一個從有線符號集合(set)中選擇符號,再放射出去的源(source),舉例來說有個集合{0,1},依照排列組合可以將這集合組合成{0,1}、{00,01,10,11}、{000,001,010,011,100,101,110,111}.....等。
源模式(source model)能夠估算一個有限符號集合所產生的符號串所代表的資訊,其中有離散無記憶源(discrete memoryless source, DMS)和馬可夫過程(Markov process)。
假設有一含有q個符號s1...sq的符號源,每個符號出現的機率是p(s1)=p1....p(sq)=pq,若接受到一低機率出現的符號,會較為驚訝,也就收到較多的資訊,反之則較低,而資訊量與出現機率成倒數關係。通常資訊量(I(p))表示為I(p)=log(1/p)。
熵(entropy)為整個符號源的平均資訊量,計算熵時,除了必須得到符號元的所有資訊量外,還需要設定基底,其公式為 ,r為基底,pi為各個符號出現機率。
,r為基底,pi為各個符號出現機率。
,r為基底,pi為各個符號出現機率。 唯一解碼(unique decodable)即所收到的訊息僅有一種解釋,例如S1=0、
S2=01、S3=11、S4=00,若收到0011時,可以有S4 S3和S1 S1S3兩種解釋。解碼程序,需要建立一顆解碼樹(decoding tree),如下:
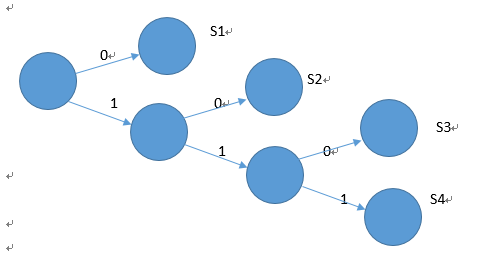
上面的例子中,解碼程序即時的,一旦一個完整的符號被接收,解碼端就不需要額外多看後面幾個位元才能確定接收到符號,故此解碼又稱即時碼(instamtaneous codes)。而即時碼必定為唯一解碼,但反之不必然。即時碼的平均編碼長度大於等於熵值。
以上是影像壓縮導論的重點整理。







