日誌2020-05-26 18:09
Beautiful Soup (上)作者:Yotsuba
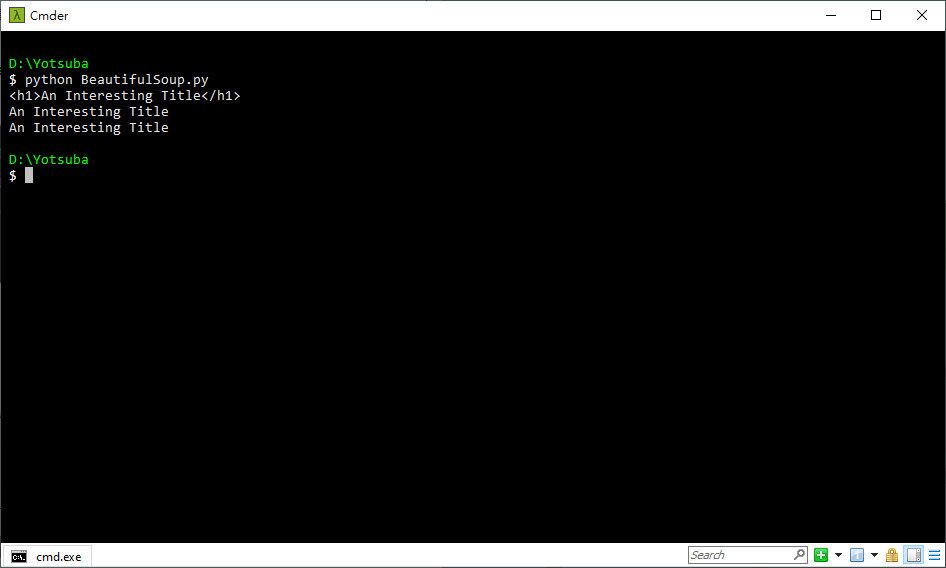
| <html> <head> <title>A Useful Page</title> </head> <body> <h1>An Interesting Title</h1> <div> Lorem ipsum dolor sit amet, consectetur adipisicing ... </div> </body> </html> |
| import requests from bs4 import BeautifulSoup response = requests.get('http://pythonscraping.com/pages/page1.html') soup = BeautifulSoup(response.text, 'html.parser') print(soup.h1) print(soup.h1.text) print(soup.find('h1').text) |



2020-05-26 22:23Yotsuba:每一個 print 都是找出 "第一個" 遇到的 <h1>,不是所有 <h1>
找出所有有另一個函式叫 find_all(),會在之後的章節解說
因為 Beautiful Soup 的用法實在太多了
即使我解說的很詳細,還是要請大家多使用 Beautiful Soup 才會熟練
假設今天 HTML 的結構裡面有
<div>Hello</div>
<div class = "hey">World</div>
無論寫 soup.h1.text 或 soup.find('div').text 都會得到 Hello
因為都是取得第一個看見的 <div>
都是一樣的節點,那要如何拿到 World 呢 ?
可以寫 soup.find('div', class_ = 'hey').text
這就是利用 class 屬性去拿到特定 <div> 的方法
注意,class 已經是 Python 的保留字,Beautiful Soup 做法是寫 class_
其實這裡有一篇教學寫得還不錯,之後的章節都會詳細談到
https://blog.gtwang.org/programming/python-beautiful-soup-module-scrape-web-pages-tutorial/
2020-05-26 22:23Yotsuba:同上
2020-07-12 18:34Yotsuba:以文章中的例子來說兩種寫法都會得到一樣的回傳值,跟「有沒有」沒關係
但是在實戰爬蟲的時候,節點可能會非常複雜,這種時候就可以用 find 去過濾ㄌ