比如說以前GPU跑的著色器平行化很好,所以效率很高,那為什麼要弄得複雜,而不是越來越高的理論值呢?
經常也是用理論浮點數這些資料當作計算力比較參考,但問題也來了,fp32這些理論指標只是一部分,往往跟其他部分綁定在一起。
這導致實際貢獻上可能誤以fp32就是GPU提升的原因,所以猛堆計算能力就是正解而其他部分不重要。
__________________________________________
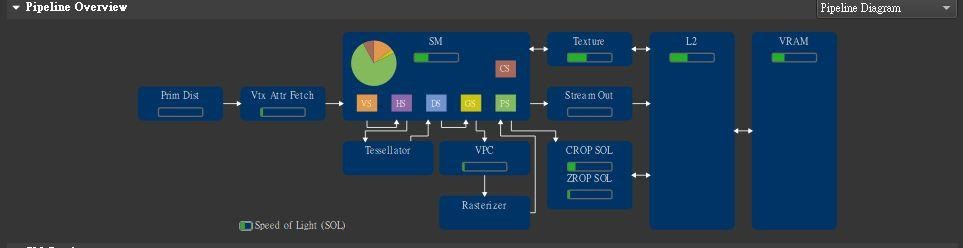
圖形負載到底在跑什麼呢?
這是某個UE4遊戲(內容不用說...)的分析結果,約70幀跑14.17ms,一幀中的利用率。
使用Nsight Graphics 2020.5.0(限定N卡 shader分析要DX12與圖靈以上 其餘功能可跑來分析)
然後看一下Render Target Ranges這項
第一個"DSV5 0.42ms -3.0%"
Top SOLs這個指標代表測量出來的吞吐量比理論峰值(無瓶頸)情況下的各單元比例。
提醒:在後面並未提及RAS所以特別解釋,這是RASTER(光柵器)的縮寫...
Graphics/Compute Idle 代表因為CPU命令而停滯比例(通常很少或等於0%)
TSL2 Stall Cycles 代表紋理失速週期,因為紋理採樣等操作發出的請求,而等待L2快取的週期比例。
其他部分就不解釋了。
SM Active 代表活動或被利用到的SM比例(例如2048個用50%=1024個)。(透過測量工作週期)
SM Active Min/Max Delta 字面意思就是最大最小的變動量。(過小代表總是在少數SM上跑)
SM Throughput For Active Cycles 正在活動中的SM其吞吐量,相比理論操作量(例如一個SM裡面有64個ALU 則需要填滿64個才能到100% 在Kepler中數值為192 maxwell與pascal為128 圖靈就不知道了...)
新增:對Nvidia給出的demo作分析,turing可能為64? 而整數被視為地址計算、部分整數計算等運用讓fp32更容易達到峰值? Ampere不知道多少
SM Occupancy(Active Warp per Active Cycle) SM的佔用率 根據活動的Warp(經線)相比活動週期。
接下來我們展開來看各參數
多出了SM issue Utillzation Per Active Cycle[%]這項 這代表調度單元利用率。
一般來說運作SM滿載利用率高的情況下,大約在50%上下,這跟架構有關係。
SM Occupancy(Active Warp per Active Cycle)則是計算出來的週期(53.35%)=17.07,100%代表32 thread(一個Warp是32Thread)
下面就不仔細解釋了,是各種調用和Warp的Launched(啟動)
右邊則相對重要,仔細了解為什麼受限(如果SM佔用率(Occupancy)都提高了,為什麼實際跑出來的吞吐量卻低?)
通常來說有三種瓶頸,計算瓶頸、記憶體瓶頸、延遲瓶頸(延遲瓶頸主要與記憶體瓶頸有關)
計算瓶頸代表計算量龐大,需要增加計算單元來加速。
記憶體瓶頸代表頻寬需求高,需要有足夠的頻寬提供資料。
延遲瓶頸代表受到延遲的限制,因為存取、計算延遲而降低利用率。
而Stall就表示當我要發射(決定要執行和給予資源)卻因為檢查不通過而停止。
Long Scoreboard指Warp停滯,因為記分板依賴L1tex(局域、全域、表面、紋理)操作,因為延遲的原因而導致的,要降低只能改善其記憶體訪問的模式(理想上是陣列)。
issue Barrier則是發射屏障,因為指令需要同步而阻止。
dispatch stalls 則是管線互鎖阻止了Warp的分派(dispatch)。
Drain因為退出的Warp正在等待記憶體寫入或像素輸出(ROP)。
IMC miss則是Warp停滯等待immediate constant cache(直接常數快取),因此需要從記憶體中進行存取。
Tex throttle則是紋理管線滿載了,紋理單元每週期可接受4個thread。(一個SM內?)
Math pipe throttle代表數學運算管線滿載(例如FMA、ALU、FP16與Tensor)
Membar 表示因為記憶體同步的屏障而停止。
MIO Throttle MIO輸入已滿 由局域、全域、共享、索引...等記憶體或其他操作引發。
Misc 無法被偵測出來的失速原因(但還是失速了)
No Instructions 沒有指令到達?
Not Selected Not Selected 是符合條件但未選擇,因為還有其他符合條件,不影響性能但會增加暫存器和共享記憶體的使用量。
Short Scoreboard 等待低延遲的MIO或RTcore資料相依性,包含很多常見的3D操作或SFU管線及其他不常見指令都有。
Wait 字面意思,因為資料依賴性而導致需要等待。
LG Throttle LSU管線已滿載,用於局域、全域記憶體指令。
Sleeping 字面意思,休眠
代表記憶體的使用,圖有點噪點和模糊...
shader 14.9%(發送請求) 而下面則是傳送給shader 4.4%(占用頻寬) 代表單元間連線的頻寬和請求。
有個>>和<<分別表示請求的方向(>>)與傳輸的方向(<<)。(在VRAM請求視為寫入 >>與<<總和最高為100%)
然後回來看DSV5的各單元 SOL
Prim Dist(Primitive Distributor) 圖元分配,進行索引緩衝區載入,並將圖元分發出去。
Vtx Attr Fetch(Vertex Attribute Fetch) 頂點屬性獲取,執行頂點緩衝區載入。
SM 流處理器,不多做解釋了。
Texture(紋理單元) 執行SRV(Maxwell開始可以進行UAV存取)
VPC (Viewport Culling) 視域剪裁 執行視域轉換、視錐剪裁、屬性透視校正。
Tessellator(鑲嵌) 與HS和DS階段有關係
Rasterizer(光柵器)進行光柵化,將圖元(三角形)轉換成像素,作為轉換的前端。
#更正:寫錯,不是頂點正確為圖元,寫的時候沒發現問題...
VS 頂點著色器 負責頂點相關的操作,傳統操作中負載大約占比5-10%。
HS 輪廓著色器 負責鑲嵌的階段,將面分割成多個三角形與幾何區塊
DS 網域著色器 負責鑲嵌的階段,進行計算修補細分的頂點。
GS 幾何著色器 在頂點與像素間的階段,將圖元內的頂點做幾何鑲嵌之類的操作或其他用途。
PS 像素著色器 與解析度有關,負載總是最大的著色器,負責將光柵化的像素操作。
CS 計算著色器 圖形負載以外的計算負載,跟異步計算有關係,提高計算管線(數學管線)利用率。
※未被列出的單元
XFB:轉換反饋的狀態包含了物件狀態與綁定緩衝區,用於幾何著色器可利用三角形帶(Triangle strip)完成想要的操作,缺點是執行效率上會不如trangle list。
Steam out 流輸出 將SM運算寫入L2。
CROP和ZROP為ROP內的分別,CROP負責像素顏色寫入與混合操作,而ZROP負責深度測試那些(例如深度剪裁)。
L2 負責過濾VRAM的操作,擁有較低於VRAM的延遲與更大的頻寬和更低的功耗,但容量有限。
VRAM 顯示記憶體 擁有最大的容量,許多內容都保存在上面。
圖中箭頭方向表示傳輸的方向。
接下來我們看DSV 305
還有RTV 105...這些
還有RTV106
還有RTV 40
以及RTV112
最後的RTV484
透過這些可以清楚看到運作階段中的變化及各種受限原因。
綜合下來的一幀
全部平均下來的使用率(一幀內)
實際下來一幀的吞吐量約37.53% 還利用了一些CS(不知道有沒有異步到成功增加吞吐)
平均下來看導致失速的原因
L2的吞吐約39.77% 紋理命中率81.66% L2命中率77.37%。
綜合下來看管線的情況
紋理占用最高 其次L2 接著才是SM和VRAM及ROP
命令的閒置與一些如切換(GPU頻率?)造成的閒置或是像素著色器實現中使用屏障同步?(優秀的可能不用?)
最終就是第一張圖的樣子
實際運作上佔比和瓶頸持續地在轉移來轉移去,由於圖形工作之間存在依賴,實際上的使用率是低的,所以當初AMD才想說因計算著色器這些來設計異步計算,試圖利用計算工作負載提高吞吐量。
但由於需要上下文切換,這些導致額外存取的頻寬開銷甚至引入延遲,所以未必很有用。
為此專門設計ACE(異步計算引擎)就是了,透過提交命令列表去用硬體檢查狀態,生成調度指令給排程,看決定是否要插入進去管線。
順帶提及HWS是全權管理GPU狀態的東西,設計在AMD的GCN上,NVIDIA的SWS跟這沒關係,而是用來最佳化暫存器和SM內狀態用的,調度的東西都在硬體上,兩者調度排程等的設計都一樣強大,但效率這些得看編譯器技術。
編譯器需要盡可能解決延遲瓶頸(資料依賴問題),從剖析資料中可以觀察的到有相當高的佔比,使得Warp發射停止,必須等到滿足條件(指令檢查暫存器狀態)。
不同編譯器和驅動執行期行為可能有不同的API開銷,沒辦法一概而論。
而AMD和NVIDIA在想辦法解決延遲上還是會殊途同歸的,因為計算機架構就這樣...。所以為了解決圖形工作負載的依賴問題而設計精細的記憶體快取階段及調度設計。
(相關內容已移至其他)
新增額外資訊:
對相對傳統的遊戲做比對一下...Unity3D遊戲(只有VS和PS)
在解析度(1600*900)下約4.08ms
在解析度(1920*1080)下約4.56ms
在解析度(3840*2160)下約10.11ms
在解析度(1920*1080)下約11.1ms(垂直同步60fps 16.6ms)
理論上來說解析度4K(3840*2160)是1080P的四倍(3840*2160/1920/1080)=4
由於頂點著色器佔比較大(不隨解析度上升),且像素著色器佔比變大,使得吞吐率從約28.3%->34.67%(+22.5%)的提升,所以最終只提升到約2.217倍的耗時。(受惠於解析度提升的吞吐)
新增對近乎純像素著色器負載情形(432p vs 1080p)
在差不多純像素負載下紋理命中率似乎有些提升(但L2大幅下降) 不過這是部分著色器 吞吐率大幅上升
命中率的變化很小,也就是平行化到更多SM並不會因此改善命中率,但是對L2的吞吐開銷會上升(VRAM也會隨之上升)。
垂直同步與不限制幀數的情況下,似乎只影響了SM活動的最大最小變化,而吞吐與Stall等都沒有變化。
解析度變高會導致有更多的Warp Stall,但沒有因此降低吞吐。
4K
1080P
因為issue Utillzation也提高了,所以Stall上升沒有太大影響。
不過過程中使用到了DSR對桌面與遊戲改變,也會影響到幀率、吞吐、延遲等,可能只是個參考就是了。
接著不使用DSR對其他遊戲採樣(對VS負載小很多的場景)
在1080P 約9.51ms下
調整到480P 2.31ms
從命中率上來看可以觀察出L2在降低解析度明顯有所提高些(72.53->77.72)(上面1080P->4K大概74.56->71.77%)
不過L2吞吐變化並沒有多少,且紋理命中率幾乎不變(不隨解析度影響?)
解析度的下降也令所有Stall都降低了,但吞吐率也從36.87%->30.88%,明顯活動與占用率都降低了,發射也從26.88%->22.79%。
9.51->2.31約4.11倍的幀率,但解析度從1920*1080->720*480,等於六倍降低。
所以降低解析度換幀率可能有些時候不划算,VS(頂點著色器)負載比例上升等影響,導致並沒有辦法解析度與幀率成比例兌換。
更高解析度雖然Stall更多,但是發射使用率、SM活動率、SM佔用率及頻寬使用都會上升,所以不會四倍的解析度就有四倍的負載佔比。
額外新增4K(含DSR影響) 31.31ms
從4K可以觀察的到VS(頂點著色器)的負載非常小了...但L2命中率大幅下降,L2吞吐不變、佔用率也沒有改變,活動率略提高。
吞吐率反而略微下降了,發射率也是。
但9.51ms->31.31ms 3.29倍(都無CPU瓶頸 即使480P也很微小影響) 似乎是來自於頂點著色器負載比例的降低影響,或著還有其他影響因素,因為理論上四倍解析度是四倍的負載。
從某些項目找到問題:
4K時
1080P時
480P時
可以發現Draw call上升了(正常來說不隨解析度影響 因為Draw call會影響CPU使用率)
一般來說
4K
1080P
720P
可以觀察得到Draw call幾乎沒變化 可以說是誤差
然後我們比對著色器片段:
4K 174676923
1080P 44703604
720P 22580540
4K比1080P->3.9倍(解析度4倍)
1080P比720P->1.98倍(解析度2.25倍)
比對Early Z Passed
4K 371363798
1080P 93450701
720P 44867550
4k比1080P->3.973倍(解析度4倍)
1080P比720P->2.082倍(解析度2.25倍)
比對Early Z Failed
4K 25364958
1080P 6563072
720P 3142328
4k比1080P->3.86倍(解析度4倍)
1080P比720P->2.088倍(解析度2.25倍)
略過Clip Primitives
比對ZCull Samples Tested
4K 433997184
1080P 155161600
720P 100790336
4K比1080P->2.8倍(解析度4倍)
1080P比720P->1.54倍(解析度2.25倍)
比對ZCull Samples Failed
4K 36698516
1080P 14577864
720P 9076612
4K比1080P->2.52倍(解析度4倍)
1080P比720P->1.6倍(解析度2.25倍)
Early-Z是提前Z-test 用來在片段著色器(FS)也稱像素著色器(PS)根據Z-buffer(深度緩衝區)提前剔除,節省大量運算的方法,但在具有透明度的物體時會失效。(特性可能會變?)
而一般ZCull是在片段著色器後面進行剔除像素後給CROP混合輸出。
回到那個像素著色器負載且draw call隨解析度改變的項目比較一下。
4K
1080P
480P
比對著色器片段
4K 370782569
1080P 100149666
480P 19179473
4K比1080P->3.7倍(解析度4倍)
1080P比480P->5.22倍(解析度6倍)
比對Early Z passed
4K 538696277
1080P 169032324
480P 45742417
4K比1080P->3.187倍(解析度4倍)
1080P比480P->3.696倍(解析度6倍)
比對Early Z Failed
4K 110102205
1080P 10348610
480P 2571681
4K比1080P->10.6倍(解析度4倍)
1080P比480P->4.02倍(解析度6倍)
比對ZCull Samples Tested
4K 598521952
1080P 221104320
480P 99664832
4K比1080P->2.7倍(解析度4倍)
1080P比480P->2.218倍(解析度6倍)
比對ZCull Samples Faild
4K 77909468
1080P 34826672
480P 15452864
4K比1080P->2.237倍(解析度4倍)
1080P比480P->2.253倍(解析度6倍)
這一翻比對下來可能跟Draw call和Early Z(提前的Z-test)有關係,Early Z Failed代表不通過測試而passed 則代表通過。
而通過的像素才會進行片段著色器(像素著色器),從通過的數量來看只有3.2倍左右,所以才會提升如此多。
也就是可能除了頂點著色器負載外還有深度測試(提前)(Early Z)的影響(一般深度測試在像素著色器後),已經過了PS(FS)無法節省頻寬與計算量。
影響很大,得看透明度測試或深度變化,如果使用Texkill(根據紋理座標,若座標有小於0則清除紋理)就會影響到後續流程。
但目前硬體設計在以前(至少費米、GCN之前)會根據不同draw call分開影響,所以目前draw call使用到有影響的特性,但到下一個draw call並不影響其Z-test。
而Z-test可能會在高解析度時對像素著色器(使用到TMU/ROP/ALU)有所節省,硬體改進與軟體方面結合從而適用更多情形(盡可能剔除)。
這才導致了分析結果看起來不一樣。
其他內容(翻修)
在RDNA和Turing上都分出了L0指令快取(RDNA還有16KB的常數(紋理)32-way?)
Turing為16KB 4-way RDNA為32KB 4-way(修正),指令設計一個依據GCN傳承而來依然是32-64bit變長指令,而另一個定長且保留些位元的128bit(在Volta以前數代都為64bit)。
每個子核有1個指令發射設計為16KB RDNA在雙CU內有四個指令發射設計為32KB
※雙CU單元的4個指令發射共享1個32KB(4-bank、64bye/line、128line、32Byte/clock 4*64*128=32KB),而per SM內有四個指令發射分別獨享??? 4-way 16KB共64KB。
RDNA指令快取每週期可供應32byte(通常約2-4條指令)(一條指令約8byte~16byte(?))給每個SIMD32 在沒有bank conflict的情況下共可以供應128byte?
在Turing上還有獨立的L1 46KB指令快取和L1 2KB常數快取(在SM內獨享 對分區來說共享指令與常數)
指令頻寬需求隨著排程的原因而變高,頻寬不夠而利用率低可能是因為各種原因停滯(失速、Stall),導致dispatch port(分派端口))不會發射,這點要注意多半是利用CUDA做極限的吞吐(計算工作)時會注意的。
一些架構設計細節稍微講一下,比如RDNA 在調度指令只需要一週期,而Turing卻要兩週期,但是一個是雙發射(CU內有兩個)和四發射(Turing內四個子核),還有BRU(分支單元)等等考量。
對於子核內有五個還七個執行單元的端口,端口下掛著怎樣的執行單元就看GPU架構師怎搞了,共享端口的情況下是無法一到二週期(甚至更長)內用來發布其他工作。
新增:
實際上可能不只一個dispatch? warp可以發射到math dispatch unit來發射而fp32與int32可以發射(都為兩個週期延遲) 對於MUFU(實際是SFU)則為32/4=8週期。
warp scheduler也可以選擇發射分支(1個分支需要4週期)或UDP(統一資料路徑)和MIO佇列及tensor core或fp16。(從2 warp instr/clk -> 1warp instr/clk 然後math dispatch unit縮減為1個)
目前都用wave32或warp(兩者都32thread) 對於SIMD32的RDNA只需要一週期就可以發射完成,而Turing因為SIMD16則兩個週期。
對於每個SM分區(子核)來說Turing的指令發射等於只要一半週期就可以,所以才會在 ampere中重用資料路徑,使得調度有足夠資源允許再發射一個SIMD16(fp32)(因充裕的L1頻寬等等資源)。
對於計算能力來說有所提升和同時可以發布更多,不過RDNA的設計和Turing設計雖有相異但實測吞吐大致上差不多(除了少數情況會依賴其他特殊單元吞吐限制)。
分支和細分一個核心這些考量都是為了延遲,在IPW(Instructions Per Warp)來看最常見就是條件執行這些造成延遲,使得核心負載不平衡,而導致延遲降低效率。
這些屬於ILP(指令級平行)的考量,從IPC上看
在kepler上有4個Warp Scheduler和8個dispatch Unit而maxwell也是,只是做了分區的管理和獨享資源,主要是新增大量資源和獨享化的設計,導致效率提高。
因為SIMD32 所以8個dispatch unit在kepler時期內足以讓6個滿足還可以跑其他指令,看起來很好,但由於暫存器等限制,編譯器可能要想辦法好好解決這些問題才能提高效率,因而分區實際上跑SIMD32*4而不是SIMD32*6,再加上充足資源提高效率,最終實現了高吞吐。
不過類似的GCN(與kepler差不多同等級)在後續持續改進解決這些問題,從而提高吞吐,不過最終還是想辦法耗費大量電晶體和重新設計減少延遲。
到了圖靈以後進一步從以前6~8的ALU延遲週期降低至4個週期和修改了調度(現在TPC內2個SM跟以前1個TPC 1SM相當的ALU) 一番取捨下來和增大暫存器及一系列設計盡可能保證降低延遲。
調度、排程這些設計是為了尋找到或減少最大延遲影響(在不同區塊或階層上),規避太慢(盡可能讓需要保證正確和一致性的資料保存在最快的地方,相對不重要就排序在後面,最終平衡下來在有限資源內最大化吞吐)
設計這麼多單元和堆砌,是為了在圖形工作的依賴限制下盡可能加速,使得一幀的時間盡可能少,最終到達很高的幀率,而因為著色器編譯後在像素著色器這些階段因光柵化分塊到各個SM上所以平行化看起來很好,但實際上使用率和IPC會隨規模下降或受限。
所以對一個GPU來說運作一個需要極高負載的shader要是平行化負載不好,可能資源被請求卡住,導致使用率看起來高,但實際效率並不好,如果跑多個並行程式可能更好?
題外話:
如果說到作業系統排程則是考量反應時間與CPU使用率,比較仔細的部分則是CPU在考慮,或thread安排可能會更改(降低核間延遲),不過這種通常都是寫程式控制或CPU中的匯流排設計規避。
2020/10/07
RDNA在L2與記憶體控制器上設計為四個區塊,每個區塊內有一個L2(1024KB)及GDDR6控制器(64bit),每個控制器可以連兩個16Gbits的32bit GDDR6顆粒。
可以對L2設計切片到64KB~512KB/slice,每個slice在RX5700XT上設計為256KB,可對記憶體控制器提供32byte/clock。
對於RX5700XT的記憶體控制器來說,在一週期內最大可以提供16*32byte(512byte/clock)給控制器(理論上2Ghz約1024GB/s 不過實際上256bit的GDDR6 16Gbits是512GB/s)
對於一個slice到L1為64byte/clock,也就是1MB(4個256KB)可提供256byte/clock,而四個區塊共1024byte/clock,對於2Ghz的GPU來說最大可以提供2048GB/s(相當於16Gbits記憶體顆粒的四倍)。
L1/L2均為128byte/line L1有4bank L2為slice。
Turing在L2與記憶體控制器上設計為十二個區塊(TU102),每個區塊內有一個L2(512KB)及GDDR6控制器(32bit)和8個ROPs,每個控制器可以連一個16Gbits的32bit GDDR6顆粒。
相比於上一代Pascal 每個分區的L2 size從256KB提升至512KB。
Turing主要改善了對寫入幀緩衝區的硬體壓縮技術,減少了頻寬與資料量使得有效頻寬更高。
每次L1 cache可以讀取64byte,頻率1.59Ghz情況下可以提供100GB/s多頻寬(turing)
L2的區塊來說可提供128byte/clock(?),也就是6MB(12個512KB)共可以提供1536byte/clock,對於2Ghz的GPU來說最大可以提供3072GB/s,這相當於384bit 16Gbits GDDR6顆粒四倍的頻寬。
※(?)經由微基準測試T4 1270GB/s(實測值)運作於1.59Ghz對吞吐率反推理論值
12個2Ghz的控制器每個週期32byte*12=384byte,總計約768GB/s。
並未提及是否可以靈活設計配置(硬體選擇設計為256KB或1024KB之類和控制器的互連)。
32-cycle: warmed line access• 188-cycle: L1 miss and L2 hit• 296-cycle: L2 miss and TLB hit• 616-cycle latency: cache and TLB miss
上述資料查找多個一致,在L1擊中情況下有32個週期延遲,在L1 miss到L2擊中約 188個週期,在L2 miss擊中記憶體內查找約296週期,在TLB miss查找記憶體最大延遲來到616週期。
在GCN時,根據GDC2018 presentation on graphics optimization.
![]()
L1擊中週期約114週期,L1miss而L2擊中時為190個週期,當L2 miss擊中TLB時約350週期。(未擊中可能來到700週期?)
可以看到GCN的在只有兩級(L1與L2)時代價似乎有點高昂。(Earlier architectures employed a two-level cache hierarchy.)(早期的架構二級快取結構)
並未看到具體的延遲資料,不過表示平均記憶體延遲(來自快取階層改善)約10%。假設要將L2的size擴大考慮電路同步可能會降低整個GPU的速度或增加L2的延遲?
(L0為原先L1?相對延遲降低(-21%),L1+L2延遲共(-24%),記憶體延遲(-7%),不好進行換算)
而RBs(ROP分區)走L1,其L1 size為128KB,且本身有小尺寸的cache(可能很小?在數KB size)
2020/10/09
比對兩家暫存器和快取與記憶體頻寬等資料(根據上述查證計算) ,在2Ghz計算出2070super與5700XT
內容不包含指令、常數或其他快取。
2070super
通用暫存器:10240KB(256KB per SM) 頻寬:40960GB/s(SIMD16*4byte*4*2)
L1:3840KB(96KB per SM) 頻寬:5120GB/s(128GB/s per SM)
L2:4MB(512KB per Controller) 頻寬:2048GB/s(256GB/s per Controller)
Memory:8GB (1GB per 32bit) 頻寬:448GB/s(1750Mhz 56GB/s per chip)
5700XT
向量通用暫存器:10240KB(256KB per CU) 頻寬:20480GB/s(2vGPR*32lane*4byte)
LDS:5120KB(128KB per CU) 頻寬:20480GB/s(32bank*2array*4byte*CU)
L0:640KB(16KB per CU) 頻寬:10240GB/s(256GB/s per CU)
L1:512KB(128KB per Shader Array) 頻寬:4096GB/s(1024GB/s per Shader Array)
L2:4MB(1024KB per Controller) 頻寬:2048GB/s (512GB/s per Controller)
Memory:8GB (2GB per 64bit) 頻寬:448GB/s(1750Mhz 56GB/s per chip)
其他:Turing上L1設計為32bank 每bank 4byte,理論上可以到達128byte/clock,但根據基準測試為64byte/clock。(共享記憶體情形下會設計為32bank)
RDNA的L0和LDS在WGP(相當於TPC)中可以調整共享,一般SIMD32對應一個LDS(64KB)及存取共享的L0,在WGP中可以視為共享的四個LDS容量與兩個L0容量。
※兩者微架構在dispath及ISA的部分如Turing有暫存器快取(少量)可避免bank conflict,一些地方不太相同可能無法直接比較。
※將FMA理論值改為vGPR計算,在RDNA中一個SIMD擁有128KB VGPR(32lane*4byte*1024)則共有32lane*4byte*2的頻寬。
※在Turing暫存器堆中設計為2bank 每bank double 32bit port可以減少bank conflict,不過計算上來說暫存器寬度至少需要thread*4byte(SIMD16*4byte),純fp32在每SM上需SIMD16*4byte*4的頻寬,且整數可以一起運作至少要SIMD16*4byte*4*2。
※在以前的架構中,每個暫存器堆有4bank,每bank為32bit,相比之下bank conflict機率較高。
※後續架構更改
僅關注頻寬
RDNA2開始,L2到L1的頻寬從1024byte->2048byte/cycle(維持256bit控制器分區對應)。
RDNA3後,L2到L1的頻寬從2048byte->3072byte/cycle(與RDNA2記憶體控制器分區相等,只是提升為384bit)所以記憶體頻寬通道也提升為1.5x,但Infinity Cache部分則增加為2.25x,從原本1024byte(RDNA2開始)提升至2304byte/cycle,相當於每個控制器部份對應提高為1.5x。
L0部份從16KB提升至32KB,L1到L0及WGP等等許多複雜的部份由於總數增長為原本的1.5x,頻寬從RDNA2的組成共4096byte/cycle提升至6144byte/cycle。
Ampere因應雙發射(實際為交替發射)fp32,充分利用更多暫存器而將L1中負責圖形負載的部份翻倍,從32KB->64KB總數也提高至128KB(增加33%)。
同時頻寬也從每個SM的單週期64byte/cycle提升至128byte/cycle(32*4byte)。
L2每個分區沒有任何說明是否提高了頻寬,可能保持在相當高的效率,這使得GA102能在測試中測量出2500~2700GB/s的數值。
Ada架構相比Ampere在主要圖形的微架構上不包含光線追蹤等等...並沒有過多改進,但在L2單元上擁有更大的容量,同時延遲週期也比Ampere更低,這可能是在硬體設計上有不同的變化(?)。
頻寬部份根據多個測試結果,相比Ampere實測值是接近翻倍的,但考量到兩者運作頻率,Ampere到Ada是從1.7~1.8Ghz提升至1.9~2.4Ghz(這裡指L2),提升約33%的頻率下也提高了更多L2的頻寬,但目前尚未知道是怎麼提升L2的頻寬的,推測可能是增加半倍多的寬度?。
延伸
2020/10/12
記憶體控制器使用率
對於記憶體控制器的使用率,可能有一個誤解就是,沒有到相當高的使用率甚至滿載,就不算是瓶頸。
實際上在GPU-Z這類軟體中採集到的也確實是相應的記憶體控制器使用率,只是沒辦法反應短時間內瓶頸轉移所產生的影響。
且實際上的記憶體頻寬,相較於理論值,通常會低一些(實際可達頻寬可能是理論的70~90%),看不同架構設計的互連與行為。
在一幀的時間內有不同的Shader在運作,通常可以構成一個個階段,每個階段多少都會佔用到顯示記憶體的頻寬。
為了掩蓋顯示記憶體較高的延遲與其較低的頻寬通常會進行空間上的預取,所以使用率高未必會影響到其運作時間。
但假設延遲不變的情況下降低了頻寬,對於出現需要存取顯示記憶體且有頻寬瓶頸特徵的階段,其時間佔比會隨頻寬下降而增加。
而一般計算過程需要存取到顯示記憶體時,也會有很短的頻寬需求,若頻寬越少,則這個短時間佔比越高。
(1)
假設一個3ms的Shader,其中存取顯示記憶體需求頻寬佔比耗時約5%,當可用的存取頻寬減半則耗時會增加5%,則理論上最終耗時會變為105%(3.15ms),當假設加倍其存取頻寬其耗時會降低至97.5%(2.925ms)。(實際上可能不會如此理想,還存在有效頻寬的下降)
(2)
而如果是大量讀取和寫入的Shader(100%佔比),且無法掩蓋其耗時,則假設耗時約5ms,當可用存取頻寬減半時,耗時會增加100%,則最終耗時會變為200%(10ms),當假設加倍其存取頻寬時其耗時會降低至50%(2.5ms)。(實際上也不會如此理想,有效頻寬並不會等效變化)
那麼假設(1)的情形占比40%耗時,而(2)的情形占比30%耗時,其餘情形為可預取並掩蓋影響則:
加倍記憶體頻寬時,40%*97.5%+30%*50%+30%=84%耗時,相當於1.19倍的速度。
半倍記憶體頻寬時,40%*105%+30%*100%+30%=132%耗時,相當於0.758倍的速度。
然後除開(1)與(2)的情形,佔用約10%記憶體控制器的時間則:
作為標準的記憶體頻寬時,40%*5%+30%*100%+10%=42%。
加倍記憶體頻寬後,40%*2.5%+30%*50%+10%/2=21%。
半倍記憶體頻寬後,40%*10%+30%*200%+10%*2=84%。
但現實中實際佔比變化可能不會如此明顯還有許多影響因素,比如記憶體頻寬足夠且能預取,速度提升很少。
而記憶體頻寬不夠且能預取不多,從而導致記憶體頻寬減少對速度的降低相當顯著。
架構不同的規格和運作負載其參數的變化都可能影響預取,所以不會有如此理想上的數值變化。(當影響從顯示記憶體被卸載到L2時,影響就不會是如上)
題外話:就算純頻寬瓶頸,單純提高記憶體頻寬會受到其他限制,比如填充率或其他部分,所以就算不估計延遲影響而最大化吞吐,假設填充率方面讀取64byte+寫入16byte,就算該週期能提供共128byte,也得按照80byte算。(所以一般只有瓶頸會變慢而不會解決瓶頸後越變越快)
(平均來說每個填充率理論上對顯示記憶體頻寬佔用大概約0.7byte~1.*byte,不同架構與場景會影響不少(採樣不同遊戲))
單論L2和記憶體控制器本身可以到理論值,但L2本身若無持續讀取寫入,也不可能持續供給這麼多需求,所以單論本身而不考慮其他限制是不可能的。
(在幀緩衝區讀取與寫入未必內容是有壓縮的,所以每個像素可能高達16byte也可能少到0.xbyte,這導致在分析計算的時候會迷惑每次運算導致的頻寬,需要檢視資源才能了解少數片段為何擁有相當高的記憶體頻寬需求)
假設負載完全以頻寬為主,並忽略延遲及其他影響,考慮到L2。
有80%的負載是需要L2頻寬與顯示記憶體頻寬,其負載尺寸與需求為:
2MB(10GB)+8MB(2.5GB)+32MB(0.625GB)+128MB(0.15625GB),一共需要170MB的資料時。
在一個4MB(1000GB/s)+8GB(200GB/s)規格下則耗時為
2MB(10ms)+2MB(0.625ms)+6MB(9.375ms)+32MB(3.125ms)+128MB(0.78125ms)一共需要23.90625ms的時間用來跑這80%負載。
以此為標準時則100%負載約29.8828125ms。(20%負載耗時5.9765625ms)
改為在8MB(2000GB/s)+8GB(400GB/s)規格下耗時為
4MB(5ms)+4MB(0.625ms)+4MB(3.125ms)+32MB(1.5625ms)+128MB(0.390625ms)一共需要
10.703125ms來跑這些負載。
以其他負載耗時5.9765625ms計算,一共16.6796875ms。
改為在8MB(2000GB/s)+8GB(200GB/s)考量記憶體頻寬並未翻倍時(或可視為記憶體頻寬減半)
4MB(5ms)+4MB(0.625ms)+4MB(6.25ms)+32MB(3.125ms)+128MB(0.78125ms)一共需要15.78125ms來跑這些負載。
以其他負載耗時5.9765625ms計算,一共21.7578125ms。
改為在2MB(500GB/s)+8GB(100GB/s)規格下耗時為
2MB(20ms)+8MB(25ms)+32MB(6.25ms)+128MB(1.5625ms)一共需要52.8125ms來跑這些負載。
以其他負載耗時5.9765625ms計算,一共58.7890625ms。
在四種情形下速度分別為33.5fps、60fps、46fps、17ps,分別在一幀內VRAM使用率(頻寬)為44.4%、30.4%、46.6%、55.8%。
實際上可能有比較複雜的變化很難計算,所以最好還是以測量為準。
共享記憶體
從分析來說記憶體控制器是不會隨時活動的,代表有許多可以利用的空間。不過這並不代表說GPU只使用了30%,那麼其他共享VRAM的設備便可以利用完剩下的70%,並且還不影響速度。
實際上得看一幀內是怎麼運作的,比如說CPU與GPU共享可以提高利用率,不過要是從短時間上來看,假設發生交疊(需要同時使用記憶體控制器),那實際上會怎樣?
從調查到的資料顯示,並不會因此發生衝突而導致例外(異常),以導致額外的不少時間開銷,在異構系統上保持一致性時,會根據隊列來存取。
假設說剛好同時的時候,CPU存取的記憶體時間可能會因此變長些,或是GPU存取記憶體的時間變長。
CPU可能會考慮使用亂序執行掩蓋延遲,從而不影響或降低影響時間,而GPU則需要等待一段存取記憶體時間。
當GPU使用了30%的時間,而CPU使用了10%的時間,且會發生使用時間上的重疊,無論是否CPU使用亂序執行使用率都為40%。
CPU的耗時會根據記憶體本身的延遲與是否可以亂序執行來決定,還有其負載佔比,而GPU存取記憶體的頻寬視同下降,看重疊的時間佔比和調度。
不同的記憶體來共享,不同排程策略及延遲和對記憶體控制器發出要求的時間點等影響,會導致結果不同,假設在一幀內不同設備彼此交錯不重疊時間,則理論上利用率最大且不因共享而導致速度下降。
但由於不同設備運作複雜,最好需要透過剖析器對多個設備進行分析與考量,從而嘗試錯開以避免排隊造成的額外時間成本。
對於非共享記憶體的情形下,透過PCIE匯流排通常是異步提交來免除延遲影響,而CPU與GPU不用考慮是否同時讀取記憶體的問題。
參數
在Nsight這個工具裡面的Range Info中Primitives指的是圖元,比如線段、三角形、四邊形為一個單位,這個單位並不是頂點,多個頂點為一個圖元作為處理的單位。
一般來說頂點至少是圖元的兩倍甚至更多,假設一個四邊形以兩個三角形組成共有四個頂點兩個圖元,則比例為2個頂點:1個圖元。
Shaded Fragments[thread]以執行緒為基礎,每個執行緒有一個或多個像素,其他項目如通過及不通過的單位為像素。
Early Z以2*2(quad)四個像素為基礎進行一次剔除與檢測,而ZCull以tile為基礎(4*4~16*16通常為16*16)進行一次剔除與檢測。
所以ZROP分析其shader的時間與使用率會得到每次檢測相當多的像素。
而CROP則根據通過的像素量進行混合,例如1080P(2,073,600個像素),實際上可能約需要花掉3Mpixel的吞吐量(效率不會是100%)
一些情況下計算出的來數值會低於通過的像素量(Z-Cull),是因為一些片段可能會被丟棄。(片段被禁用顏色混合(不規範的整數)或是混合模式影響?)
儲存(store)會計算進ROP裡。(儲存(store)為write、載入(Load)為read)
紋理採樣與過濾則會在像素著色器階段影響(負載可能含Load),根據使用到的紋理資源與複雜度、命中率、停滯週期等綜合影響,會比較難計算。
Texture mapping unit
上面寫了SRV與UAV在TMU,但尚未寫明這些是什麼。
SRV是一個可讀且保證順序的紋理資源,而UAV是未排序的紋理資源。
為了保證順序,SRV是不允許寫入而是唯讀的,因為在結構上不適合寫入。
而UAV則不只是讀取還允許寫入,這是硬體需要支援的特性。
在只保證讀取的情況下,一個已經排序的陣列可以以二分搜索(複雜度為nlogn)進行像素的搜索,但不適合使用插入尤其是隨機的,也就是如果要搬移資料寫到其他位置上效率會低下。
在鏈表(實質上是鏈結的陣列)或較寬的樹(一個分支下擁有相當多節點),這些資料結構適合隨機的插入。
不過可能在節點上會做壓縮的設計減少不必要的儲存空間開銷。
不同微架構上的LSU(載入儲存單元)和紋理單元比例與規格有所不同,會產生不一樣的開銷。
可寫入的資料結構允許面對更複雜的使用,帶來重用紋理資源以提高一些Shader的效率。(一些使用場景上可能UAV比SRV快得多)
資源視圖是Directx中的概念,代表給GPU使用的資料結構,有著不一樣的設計。
以下是常見的:
常量緩衝視圖(CBV)
著色器資源視圖(SRV)
亂序存取視圖(UAV)
採樣器視圖(SV)
彩現目標視圖(RTV)
深度樣板視圖(DSV)
不同資料結構需要考慮使用場景以進行設計,根據資料的使用特徵從簡單到複雜地,例如陣列的構造每個像素儲存的額外負擔少得多。
而鏈結串列或樹是以節點作為單位,從而讓寫入的影響變得小,從而透過移動節點而不是內容本身效率高得多,但卻要付出更多儲存空間的代價。
節點本身也能進行壓縮,但壓縮節點的設計會導致解壓縮需要存取關聯的節點才能還原節點資訊,算是較高階的設計,從而權衡儲存與速度來更快。
視圖於DirectX 12中稱呼為描述符,類似於檔案描述符,對於需要使用到的資源需要通過描述符才能綁定至Shader上。
具體作用為標記這些資源較為具體的訊息,例如是否可讀寫可多執行緒和哪個DirectX設備和工作在哪個管線階段上。
Shader->View(Descriptor)->Resources
著色器並非一定需要描述符的資訊才能進行對資源的操作,也可以直接透過指標(相應地址)從而直接存取資源。
類比成一個被封裝的資料結構,例如動態陣列(例如C++中的vector),可以常用且標準化,易於使用,但也可以不使用而直接存取位址,但可能帶來複雜度。
用語
bank:在GPU內指的是邏輯的儲存庫,透過bank可以每次查詢到對應位址的內容,例如每個bank有4byte,在讀寫時相當於佔用一個4byte寬度的通道,如果有32bank且每個為4byte且單位時間內個別映射不發生衝突,就能一次讀寫128byte的內容且延遲最低。
block:在記憶體上物理的儲存區塊,例如4KB一個block每次bank要讀寫內容的位址就會對應到相應的block完成讀寫。
page:代表記憶體的虛擬地址,透過邏輯地址來存取內容而不是物理地址可以更有效利用滿記憶體的空間與時間,也避免不同內容卻有相同地址的問題來隔離程式,更安全更簡單使用,一般來說每個page大小預設在4KB,不同應用下設計可能有4KB、64KB、2MB、1GB這些對應。
TLB:加速page的虛擬到物理位址(或作實體位址)轉換,是一種特殊的cache有著自己特定格式,結合作業系統或驅動程式這些以管理或發出指令的方式完成工作,一般設計上是能通用其儲存空間,可以支援更多尺寸與模式,不同地址與模式間需要發生切換沖刷的工作。(可能有辦法避免過高的開銷(?))
假設在4KB一個分頁項,32bit從高位切20bit,後面12bit因為是分頁4KB(2^12)是分頁內指令或資料保存的位置可以忽略,用來保存各類旗標或訊息,所以32bit可以對應4GB邏輯空間。
以此類推64bit為2^64定址能力(邏輯位址),也只需要64bit(8byte儲存一項),在CPU上目前普遍只實作到48bit邏輯位址(因為TLB設計為4級,概念上或架構標示為2級,每級12bit而4級共48bit映射的邏輯位址,也能更快點)
儲存空間上於系統並非使用6byte(48bit)而是8byte作為一項來對齊,也方便多級分頁(比如一個分頁中儲存分頁的項,4KB可以儲存512項,當使用32bit時會儲存成1024項)。
過大的分頁(當單一分頁對應的不是4KB而是更高)會導致在硬體查詢轉換上更慢,以致於寫入內容時更慢(?)所以必須權衡取捨。
※看情況新增
 想說來寫看看,GPU越來越複雜是正常的,但你可能會很難理解為什麼?
想說來寫看看,GPU越來越複雜是正常的,但你可能會很難理解為什麼?